
A couple weeks ago I was reading about some Supreme Court decisions, and I recalled reading a really interesting article about overreach from the Supreme Court. But I couldn't quite remember the name from the article. It was something about the power or overreach and the Supreme Court, as I remembered it. So I went into my web browser and searched all around with queries such as "supreme court overreach" or "supreme court too much power." After a good bit of internet searching I eventually did find the article I was thinking of. But I was really annoyed at how long it took me to find an article that I've already read. So I went to bookmark it, and I found that it was already bookmarked!
The title of the article is The Immense and Disturbing Power of Judicial Review. So when I searched "supreme court …" the bookmark didn't show up. I would have had to specifically remember that the title started with "the immense and disturbing …" or that it contained the words "judicial review." Even though the words "supreme court" are scattered throughout the article, the article would never have shown up in my bookmarks because regular bookmarks in the browser do not search through the contents of the article.
This has happened to me several times in the past, where I remember some part of an article that I've read, but I don't remember the exact title. And it's been very frustrating. My internet searching skills are very above average, but it bugs me that I have such trouble searching for an article that I've already read and even more so searching for an article that I've bookmarked for later.
When searching for an article on DuckDuckGo, Bing, Google, etc etc, you're searching for every single webpage that they've saved in their indices. That's nice if you don't know exactly what you're looking for, but in my many cases there's too much noise to filter through to get to what I actually want, and what I've possibly already read myself.
The Search For a Bookmark Manager
With the amount of bookmarks I make every day, I need a bookmark manager. I read a lot of news articles, editorials, dev blogs, tutorials, Wikipedia articles, you name it. And whenever I read anything at least mildly interesting, I instinctively press ctrl + d then enter to bookmark the page. Just yesterday evening from my count, I bookmarked 15 pages that I thought were interesting! Now imagine that every day! Adds up pretty fast.
The first obvious bookmark service to look at for me was Pocket from Mozilla. Every time I install Firefox, the first thing I always do is get rid of the Pocket icon. But maybe it could easily solve my problem. From a brief glance at Pocket, it says that full text search is only available if you pay $5 a month, so this it's a non starter already. I'm not going to pay monthly for something I could make myself and have for free forever.
But before I race off to my computer and start building something from scratch, let's take a look at some of the open source projects already out there for bookmark management. Here's the first three I looked at.
Wallabag

This is the first open source project I stumbled upon. So I deployed it on my server to test it out, and I didn't really like it. The interface is pretty clunky. And when I went to bulk import just a portion of my bookmarks, the application didn't respond for over 10 minutes.

By default it also has this feature where it will archive the page on the server, so you can read it if the original page gets deleted. But I found a lot of pages just didn't download correctly, so I just have to go to the original website anyway.
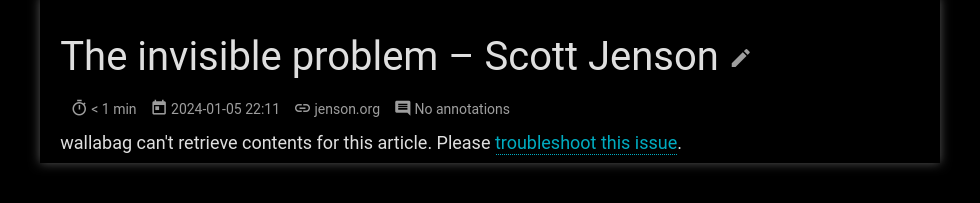
Last thing, the Firefox addon is really clunky as well. I have to give it my website URL, then a client ID, a client secret, a user login, and a user password. And I'd have to do that for all my devices too which would get really annoying
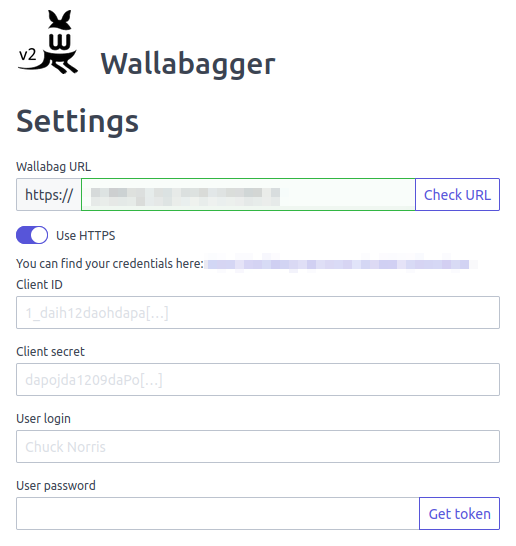
So Wallabag is a pass.
Shiori
I'll keep this one short. This bookmark manager is pretty simple. A little too simple actually. It doesn't have a decent importer and the Firefox extension is only in beta. So this is also a pass.
Linkding
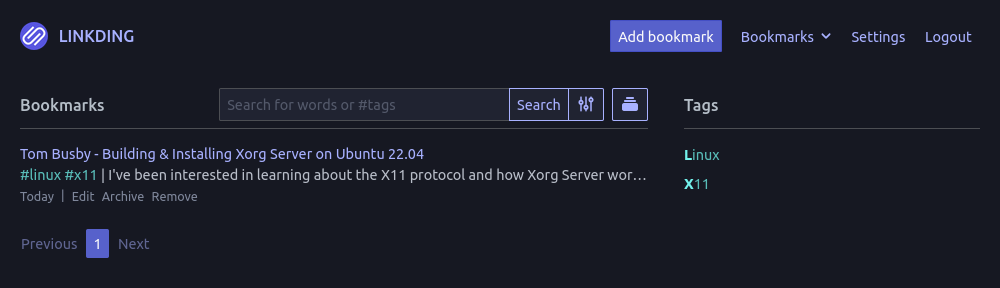
I like the user interface. It's not too busy, it looks good on both my phone and my ultra wide monitor, and it has a nice to use bookmark extension.
The one downside though is that it doesn't have full text search. It has a basic search for the title, the website meta description, and any notes you've written.But I really like the interface and the Firefox extension. It's also written in python and the codebase is really tidy. Plus it allows Postgres as a database option, which has pretty decent full text search capabilities.
So this is the bookmark manager I decided to go with. It's close enough to what I'm looking for, and I can just massage it exactly into what I want. And that's a philosophy I'd encourage you to follow with most software development projects. Try to find something that is as close as possible to what you really want and tweak it to perfection.
For example, you want to make a videogame? Use an engine: Unity, Unreal, Godot, whatever. Unless you have a really good reason to build a game engine − you're a large corporation who doesn't want to pay licensing fees, you have a narrow scope and know exactly what you're doing, you are developing for an odd platform that game engines don't support, you specifically just want to build a game engine for fun, etc etc − you're just wasting time reinventing the wheel. Time that could go towards making your game better. But I'm getting a little off topic here.
Supercharging Linkding
I'm not going to bore you a bunch of code snippets explaining how to do full text search with Django and Postgres. There are a ton of tutorials out there on the internet on how to do just that. I'll just go over the interesting parts that are relevant to Linkding.
The first thing I had to do was add a field for storing the webpage content, which I named body_content, on to the Bookmark model. Then I made a Django migration for it using the django-admin utility. And finally of the boring stuff, I just added the body_content attribute to basically everywhere that all the other attributes like the title or description are used. So at this point I just have a boring body_content attribute that doesn't do much.
The next step is updating the import script to populate my new body_content attribute. The original function only parses the header and also has a fixed parsing size limit, so I commented that out because I want the entire page. And then I made this short function to do some basic parsing on the body of the page.
def _filter_body(body):
if not body:
return ''
try:
filtered_body = body.findChildren(text=True, recursive=True)
filtered_body = list(filter(lambda text: text != '\n' and text != '\r', filtered_body))
filtered_body = (' '.join(filtered_body)).replace("\n", ' ').replace("\r", ' ')
filtered_body = ' '.join(filtered_body.split())
except:
return ''
return filtered_body
What this does is attempts to get the raw text between the html tags. If there is no body given, or an exception is raised, it just returns an empty string. It also parses everything between script tags, which is kind of annoying. But it's necessary because some progressive web apps store their information in javascript before the webpage is rendered client side, so I can't just ignore script tags. Maybe I'll go back and filter out punctuation, and maybe do some other filtering, but this works for now.
With the data in the body_content attribute, now I need to actually be able to search it. Here's the original snippet of the script that searches for the query terms, and if I were lazy I could just stick my body_content attribute on the end and call it a day.
# Filter for search terms and tags
for term in query['search_terms']:
conditions = Q(title__icontains=term) \
| Q(description__icontains=term) \
| Q(notes__icontains=term) \
| Q(website_title__icontains=term) \
| Q(website_description__icontains=term) \
| Q(url__icontains=term)
But I really want my full text search! And before I can do that I need to do some database optimizations, otherwise the searches are going to be incredibly slow!
How Does Full Text Search Work?
It's really cool and I'll explain it real quick. Consider these two phrases:
- Better late than never.
-
I've never been better.
Say we we're searching for the phrase that contains the word "been." In a basic search, both of the phrases would be scanned like so.

This has some obvious limitations. Say you entered the phrase "never better." You wouldn't get any results from either phrase. This is where an inverted index comes in. With an inverted index, the problem is flipped around. Instead of searching through all of the phrases to see if there are any matches, the phrases are divided into words. And then those individual words point to which phrases that they appear in.

There are a lot of ways to optimize full text search, such as stemming, where you take words like "jumping," "jumped," and "jumpy," and remove the ends of the words so they're all "jump" and can be searched easier. Or removing stop words, words that have no significance such as "a" or "the." There's a lot that can go into making search robust.
Optimizing My Search
Postgres has a special data type called a tsvector that is optimized for full text search, and it's supported by Django. So I put a SearchVectorField on my bookmark model, and then I added a custom migration to add the tsvector column on the table.
ALTER TABLE bookmarks_bookmark ADD COLUMN search_vector tsvector GENERATED ALWAYS AS (
setweight(to_tsvector('english', coalesce(title, '')), 'A') ||
setweight(to_tsvector('english', coalesce(description,'')), 'C') ||
setweight(to_tsvector('english', coalesce(notes,'')), 'B') ||
setweight(to_tsvector('english', coalesce(website_title,'')), 'C') ||
setweight(to_tsvector('english', coalesce(website_description,'')), 'C') ||
setweight(to_tsvector('english', coalesce(url,'')), 'D') ||
setweight(to_tsvector('english', coalesce(body_content,'')), 'B')
) STORED;
Those letters A, B, C, and D correspond to the weights of the different fields. From the documentation, the letters correspond to the following weights:
- A = 1.0
- B = 0.4
- C = 0.2
- D = 0.1
And if a weight isn't specified, then by default it's D.
Then I added a GIN(Generalized Inverted Index) Index on the model and in the table, to top it off. And now finally I need to use my newly created column in my search query function.
I deleted the search_terms loop mentioned above and replaced it with a filter on the search_vector attribute:
# Do full text search if search terms are provided
if(len(query['search_terms']) > 0):
search_query = '|'.join(query['search_terms'])
query_set = query_set.annotate(
rank=SearchRank('search_vector', search_query)
).filter(search_vector=search_query).order_by('-rank')
I also added an option to sort by relevance because the default it to sort by the date
# Sort by date added
if search.sort == BookmarkSearch.SORT_ADDED_ASC:
query_set = query_set.order_by('date_added')
elif search.sort == BookmarkSearch.SORT_ADDED_DESC or len(query['search_terms']) == 0: # If there's no query, sort by date added desc by default
query_set = query_set.order_by('-date_added')
Fixing My Django Model
If you noticed above, I made the column a generated column. Which obviously means the column is generated from those other columns that I gave it, and it also means that I can't insert a value into it.
So if I want to both have my search_vector field on my Bookmark model and eat it too be able to use it, I need to make sure that Django doesn't try to insert or update anything into this generated search_vector column. Otherwise it will throw an error.
And all I need to do it extend the insert and update functions on the model, and tell it to just ignore my search_vector field (taken from here).
def _do_insert(self, manager, using, fields, update_pk, raw):
fields = [
f for f in fields if f.attname not in ['search_vector']
]
return super()._do_insert(manager, using, fields, update_pk, raw)
def _do_update(self, base_qs, using, pk_val, values, update_fields, forced_update):
values = [
value for value in values if value[0].attname not in ['search_vector']
]
return super()._do_update(base_qs, using, pk_val, values, update_fields, forced_update)
Importing My Bookmarks
Getting the bookmarks off my phone was a pain in the ass. Firefox doesn't have a good bookmark manager on Android, and it doesn't allow you to export your bookmarks into a portable file. So I just created a temporary Mozilla account, gathered up all my smartphones, synced them one by one, and exported the bookmarks on my desktop.

I also pulled my Galaxy XCover Pro out of cryosleep and synced it too.

The bookmarks from my computers were easier to export. All I had to do was go to the bookmarks manager and click export for all my computers, and that was it.
Importing Into Linkding
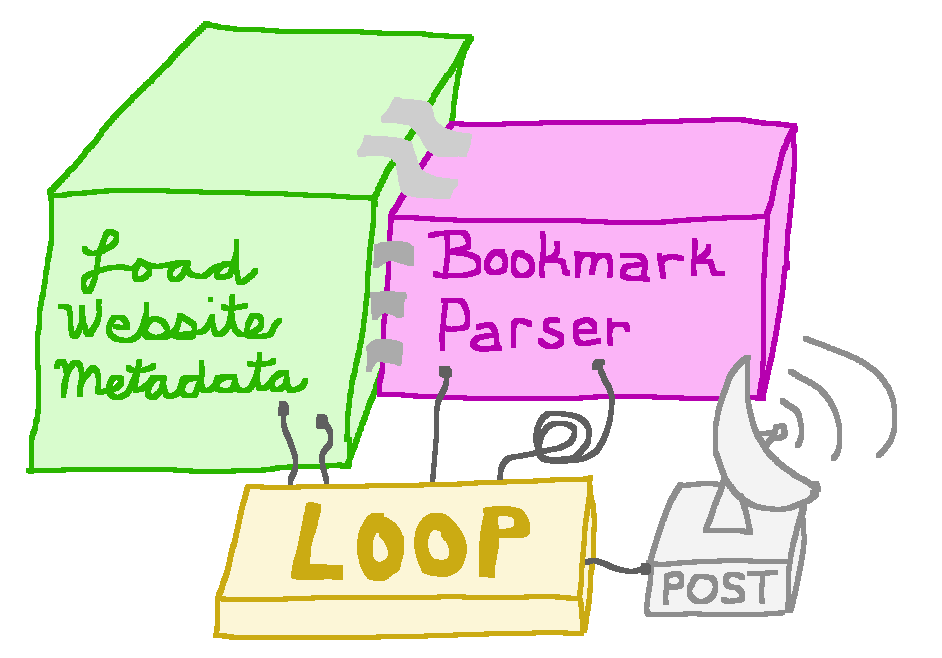
This part was a little trickier. Linkding does have a bookmark importer, but the problem is that it doesn't import any of the page data from the links, only the links themselves. But Linkding also has an API that I can post to with all the page data. This import is a one time thing, so I just hacked together an import script by frankensteining some bits of code together from the Linkding codebase. I took the load_website_metadata function, the BookmarkParser class, and all their dependencies, cobbled them together, and posted the results to my server in a simple loop. It took about an hour to import all of my bookmarks.
As of writing this article, I have 1863 bookmarks saved in Linkding. It's been a fun journey developing this. I may do some more tinkering on improving the search ranking, but for now I'm really happy with the result.